

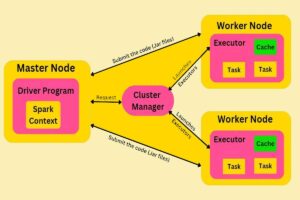
Driver is a Java process. The main() method of our program runs in the Driver process. It executes the user code and creates a SparkSession or SparkContext. The SparkSession is responsible to create DataFrame, DataSet, RDD, execute SQL, perform Transformation & Action, etc. It determines the total number of Tasks to be run by the Executors in the Worker node by checking the Lineage. Once the Physical Plan is generated, the driver with the help of Cluster Manager schedules the execution of the tasks (transformation and action) to the Executors in the Worker nodes. It keeps track of the data (in the form of metadata) which was cached in Executor’s (worker’s) memory.
The term “Driver program” in the context of Apache Spark refers to a specific component of a Spark application, and it is not a client program used to access the Spark cluster.
The Driver program is a core component of every Spark application, and its primary role is to coordinate the execution of tasks on the Spark cluster. Here’s what the Driver program does:
- Control and Coordination: The Driver program is responsible for controlling the flow of the Spark application. It reads and interprets the application code, which typically includes Spark transformations and actions, and orchestrates their execution on the cluster.
- Job Submission: It initiates the execution of Spark jobs by breaking them down into stages and tasks and sending them to the cluster’s worker nodes. These jobs are executed in parallel across the cluster.
- Data Distribution: The Driver program is responsible for distributing the data and tasks to the worker nodes. It ensures that the required data is available to the worker nodes for processing.
- Aggregating Results: The Driver program collects and aggregates the results of Spark actions, such as counting, collecting data, or writing to external storage. It then returns these results to the user or stores them as needed.
The Driver program is an integral part of a Spark application and runs on the client machine (the machine from which the application is submitted using “spark-submit”). It is not a client program used to access the Spark cluster. Instead, it acts as a central control unit that interacts with the cluster’s manager (e.g., Spark’s built-in standalone manager, YARN, or Mesos) to delegate tasks and manage the execution of the Spark application.

{kind=link}